ABAP Source Code Search using HANA Fulltext search
In a previous post I showed you how to build a SOAP message payload search using a SAP HANA fulltext index. Here I will show you how to create an ABAP source code search using the SAP HANA database (though it should work with any database that has a fulltext index feature by tweaking the SQL statements).
Over the years I have devised several ways to do an ABAP source code search, starting with Ferret (a Ruby library), then using Apache SOLR and more recently Elasticsearch. However, if you are running SAP on a database that supports fulltext indexes, there is of course no reason why you can’t just use that.
I believe that in the meantime SAP also provided some solution for this but, if I am not mistaken, it uses TREX, so if you don’t have a TREX server installed, that does not really help.
EDIT: It turns out that the SAP-provided solution is also a fulltext index solution for HANA. It requires you to switch on a business function, SRIS_SOURCE_SEARCH with the switch framework (and apparently it is reversible). You can read more about it here. It seems though that it is targeted mainly at the ABAP Development Tools (ADT) for Eclipse, as I cannot see any mention of how you use it through the SAP GUI. (There is a blog post from 2014 about it here). On the other hand, you can still roll your own as described here. It works with your existing ABAP development tools and it’s more fun to do 😉
As a matter of background: The sources for ABAP programs (including classes, function modules, other includes, etc.) are held in a table called REPOSRC, but in compressed format. To get at them programmatically, you need to use the READ REPORT statement. Trying to do a text search through everything on the system is totally impractical, but having everything indexed allows you to do instant searches across all sources.
The solution presented here consists of two programs: one is the program that does the indexing and the other is the program that you can use to search through the index. The sources are available on a Gist, for which you will find the link at the end of this post. Oh yes, and of course you need a table that will hold your data. In fact, let’s look at that first.
Create a table that looks as follows. I called mine “ZBC_SCI” and that is how it is referred to in the programs below.
+--------+---|------------+---------+------+--------+-----------------------------------------------------+ |Field |Key|Data Element|Data Type|Length|Decimals|Short Description | +--------+---|------------+---------+------+--------+-----------------------------------------------------+ |PROGNAME|X |PROGNAME |CHAR |40 |0 |ABAP Program Name | |UDAT | |RDIR_UDATE |DATS |8 |0 |Changed On | |UTIME | |DDTIME |TIMS |6 |0 |Dictionary: time of last change | |SOURCE | | |STRING |0 |0 |Source code of program (uncompressed, unlike REPOSRC)| +--------+---|------------+---------+------+--------+-----------------------------------------------------+
Here is what the table would look like (just a little screenshot to confirm):
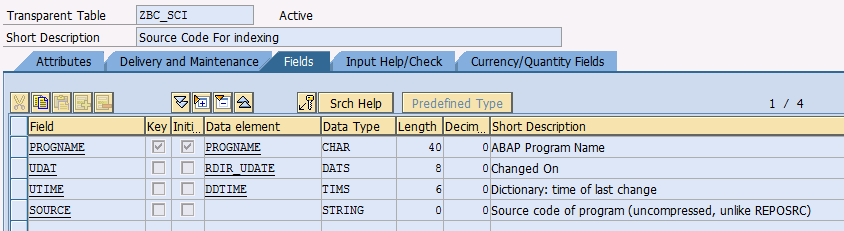
Next, let’s take a look at the indexing program.
This program has three options: 1) Creating the indexes (this is a prerequisite for actually doing the indexing), 2) Doing a full index of all the sources on the system and 3) Doing a delta of all updated programs since the last change.

In order to create the fulltext index, you need to issue a native SQL statement directly to the database; fulltext indexes are not a feature that are exposed via ABAP directly. The indexing program allows you to create the index by doing just that. In case you change and re-activate the table in SE11, chances are that the index will be dropped on the database, in which case you have to re-create and rebuild it using this program.
The program can be scheduled to run in the background at regular intervals and will, by default, perform a delta extraction. The deltas are picked up by comparing the recorded timestamp of the last change on the ZBC_SCI table to what is on the REPOSRC table; i.e. it will pick up all changes that are not indexed yet.
(I must admit that I didn’t do a heck of a lot of reading up on the various options for creating a fulltext index and I think there are some optimizations that one can make that will facilitate searches or make them a little easier).
 Next, we look at the program that executes the searches against the index. Again, it uses some native SQL statements that are passed to the database to take advantage of the fulltext index, as it is not possible to do this directly using OpenSQL in ABAP. In this program, I just display an ALV grid with the result directly on the selection screen (a technique I will discuss in more detail in a future blog post). Searches are performed by entering the search term and pressing ENTER. Double-clicking on a result takes you to the source unit (program, include, method, function, whatever).
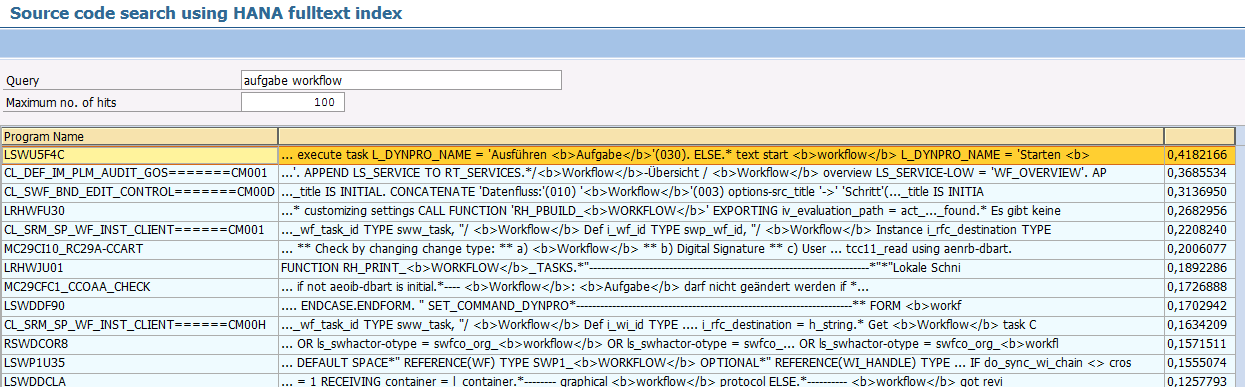 Â
Â
Again, I am sure there are some ways in which the search can be improved but, for now, it’s usable.
Lastly, here is the Gist containing the source code on GitHub:
https://gist.github.com/mydoghasworms/ba510fc4d7ba9e3f0c26495a3b901c2a
Leave a Reply